INTRODUCTIONThe ability to understand speech is an important feature to be considered during an audiological evaluation, because it allows the communicative-perceptive function to be analyzed by providing data about how the individual understands the message spoken in daily listening situations (1). Normal hearing individuals, as a rule, show a good performance in most situations; however, in noisy environments, they can mention a difficulty in understanding speech. The reason is that when the evaluation occurs during a noise, several auditory channels are required to achieve the speech recognition, indicating that more detailed sensorial information is necessary under harsh listening conditions (2).
For purposes if achieving a successfully intelligible speech, it is essential that the recognition of message characteristics and the acoustic characteristic environment should occur on a simultaneous and integrated basis (3).
The environmental has been increasingly found in people's routine, many times it may not cause any harm and damage hearing somehow; nonetheless it directly interferes with understanding words (4). Analyzing the association between the audiometric levels and the ability to recognize each individual's speech signals becomes crucial in the audiological evaluation process. The frequent complaints about a difficulty in recognizing speech, especially in noisy environments, even in individuals considered audiologically normal from the quantitative point of view (4, 5), makes us think that the individual must be analyzed in order to quantify this difficulty.
At an audiological evaluation, difficulties in understanding speech can only be really proved by speech stimuli representing a communication situation (6). Due to the risk represented by this task, its evaluation provides relevant information on the individual's ability to deal with listening in noisy situations (1).
For this purpose, the List of Portuguese Sentences test - LPS (7), using sentences as stimuli, can be applied in both silent and contrasting noisy situations. Sentences represent the characteristics of a conversation better than isolated words and, in association with noise, allow speech to be recognized by simulating situations similar to those of the individual's daily life in a clinical environment (1).
lPS provides an accuracy and objectivity to measure the abilities to recognize speech by a listener as a reflex of his/her performance in real listening situations and his/her findings are extremely important for a more accurate clinical diagnosis (6).
Based on these considerations, the objective of the present study was to check and compare the performance of normally hearing young adults with and without a clinical disorder to understand speech during noise by using sentences as stimuli when a contrasting noise is present.
METHODThis study was performed at the Hearing Prosthesis Service of Santa Maria Federal University (UFSM)'s Phonoaudiology Department (SAF) in the school year of 2009 based on the "Research and database in auditory health" project registered in the Center of Health Science's GAP under Nº 019731 and approved by the Ethical Committee in Research with a certificate Nº 0138.0.243.000.06.
Inclusion criteria were used such as: hearing within normal standards, i.e., audibility thresholds lower than 25 dB NA at frequencies between 250 and 8000 Hz (8), absence of impairment in the middle ear, as well as tinnitus disorder and hearing loss.
Accordingly, the sample was comprised of 50 normally hearing young adults aged between 19 and 32, who mentioned to have a difficulty in understanding speech during or not, and they were divided into two groups: group A, without a disorder to understand speech composed by 26 individuals - 14 males and 12 females; and group B, without a disorder to understand speech composed by 24 individuals - 7 males and 17 females.
All the participants were socially active and productive graduation or post-graduation students.
After being guided about the objectives, reason and methodology of the proposed study, the individuals signed a Free and Clarified Agreement Term. Subsequently, they were submitted to an anamnesis by way of a questionnaire collecting information on personal data, hearing disorders and otological history.
The audiological evaluation was performed after the visual inspection of the acoustic meatus and included: pure-tone threshold by air at frequencies between 250 and 8.000 Hz and by bone at frequencies between 500 and 4.000 Hz; research of the speech recognition threshold (SRT) and research of the percentile score of speech recognition (PSSR). To obtain these measures, we used: a Fonix FA-12 type I two-channel digital audiometer and Telephonics TDH-39P earphones. The acoustic immitance measures (AIM) were evaluated by tympanometry and rsearch of the acoustic reflexes by using an analyzer of middle ear named INTERACOUSTIC AZ7, with a TDH-39 phone and MX-41 pads, with a sound tone from 220 Hz to 70 dB NA, and calibration as ruled by ISO 389-1991. The acoustic reflexes were researched at frequencies of 500, 1000 and 2000 Hz.
Afterward, the research of the sentence recognition threshold in noise (SRTN) was performed and the signal/noise (S/N) ratio was calculated by applying the LPS test (7). This material is recorded on a CD and contains eight sentence lists and a speech-shaped noise recorded in independent channels, allowing the sentences to be presented in noise with different intensities of presentation. The sentences and the noise were presented by a Compact Disc Player Digital Toshiba - 4149 coupled with the audiometer described hereinbefore.
Before starting the test with each individual, the output of each CD channel was calibrated by the VU-meter of the audiometer. The 1 kHz tone present in the same CD channel, in which the sentences are recorded, as well as the disguising noise present in the other channel, were put at level zero.
The sentence lists and the contrasting noise were presented monoaurally and ipsilaterally by earphones, allowing the ears to be evaluated separately. The used sentence lists are described in Figure 1.
Sentences were applied in the following order:
a) Sentences from 1-10 on the list 1A with the presence of an ipsilaterally contrasting noise in the right ear to make the individual acquainted with the test.
b) Sentences from 1-210 on the list 1A with the presence of an ipsilaterally contrasting noise in the left ear to make the individual acquainted with the test.
c) Presentation of the list 3B with the presence of an ipsilaterally contrasting noise in the right ear.
d) Presentation of the list 4B with the presence of an ipsilaterally contrasting noise in the left ear.
The initial intensity of the first sentence of each list was based on the results found in the training described above, and the intensity of the noise remained constant at 65 dB NA (9). Hence, the initial S/N ratio started changing from the change in the intensity of each sentence.
By way of a training, it was possible to determine the intensity level required for each individual to be successful in the first sentence of each list of the test.
The strategy used to research LRSN was the sequential or customizable one, or ascending-descending (10). It enables to measure the necessary level for the individual to properly identify nearly 50% of the speech stimuli presented in a certain S/N ratio.
4 dB intervals were suggested until the first change in the type of response and subsequently presentation intervals between 2 dB stimuli until reaching the end of the list (10). However, due to the technical possibilities of the available equipment to perform this research, 5 dB and 2.5 d B intervals of sentence presentations were respectively used.
Compliant with this strategy, when the individual could correctly recognize the presented speech stimuli, its intensity was reduced; otherwise, its intensity was increased. A response was only regarded as correct when the individual repeated all the presented sentence without an error or omission.
It is important to mention that, in the first study performed with earphones (11), it was observed a 7 dB difference between the recording volume the two presented signals (speech and noise), and the sentences are recorded in a medium intensity of 7 dB below the noise intensity. Accordingly, the author of the test mentioned that in the evaluations performed with earphones, it is necessary to reduce 7 dB from the speech scores observed in the equipment dial, and such a procedure is taken in this research.
The presentation levels of the sentences were registered to later calculate the average based on the scores where there was a change in the type of response and then reduced the 7 dB, ending in LRSN. To obtain the score of the signal/noise ratio (S/N), the intensity level of the noise (65 dB NA) of LRSN score was reduced. The variant considered in the study was LRSN expressed by the S/N ratio.
The descriptive analysis of the data and, subsequently, the data collected were submitted to a statistical treatment by firstly analyzing the variant behavior. As a non-normal data distribution is found in the right ear, the Mann Whitney test was applied; after a normal data distribution is found in the left ear, the t Paired test was applied. Both tests are intended to compare whether the difference between the averages of the S/N ratios between the groups with and without a disorder was significant or not. A statistically significant level was regarded as p < 0.05 (5%).
RESULTSNext, the results achieved in the evaluation performed in the 50 individuals are presented, out of whom 24 had no clinical disorder to understand speech in noise (Group A) and 26 had a disorder (Group B).
In the statistical analysis, no statistically significant difference was evident concerning sex, therefore, this variant was disregarded.
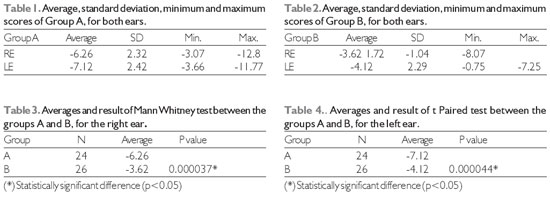
In Tables 1 and 2, the results of the S/N ratio of each group are displayed.
In Tables 3 and 4, the data obtained by comparatively analyzing the average S/N ratio by ear are displayed for each group.
DISCUSSIONThe medium values achieved for S/N ratios in the right ear, for group A (without a disorder) and group B (with a disorder), were respectively-6:26 dB and -3.62 dB. As for the left ear, values were -7.12 dB and -4.12 dB.
Based on these results, it can be verified that the average values of the S/N ratios achieved for the individuals having no disorder were better than the average values of the S/N ratio achieved having a disorder to understand speech in noise. This proves that Group A individuals succeeded in recognizing around 50% of the speech stimuli presented during a contrasting noise (65 dB NA) with a more adverse S/N ratio, i.e., the speech stimuli presented in lower intensities in relation to noise.
According to literature, normally hearing individuals can be jeopardized in communication situations in which the S/N ratio is adverse and negatively interferes with speech intelligibility (2).
Such a fact was verified in the present study, because when comparing the results between the groups, a statistically significant difference was verified in both right and left ears, revealing that the group with a disorder (B) had a significantly worse performance than the group without a disorder (A).
Similar results were found by other researchers (12,13,14).
Group A had a medium S/N ratio of -2,64 dB better than Group B on the RE and -3 dB better ion the LE. Sentence tests with a contrasting noise can prove small changes in the S/N ratio, converting them into big intelligibility changes (15).
The 1 dB range in the S/N ratio for normally hearing people represents relevant changes in speech recognition. Several studies are found in literature mentioning different range values for each favorable addition to the signal/noise ratios, such as 18% (9), 13.2%(15) and 12.12% (5), and the latter was researched with the same evaluation tool used in the present study.
Hence, the differences between the values of the S/N ratios studied here are considerably relevant, because if we use the value found in the aforementioned research (5) that found a change in the percentile score of speech recognition of 12.12 % for each 1-dB range in the S/N ratio, we could imply that Group B individuals requiring an estimated more favorable 3-dB S/N ratio to recognize 50% of speech stimuli would have percentile scores of speech recognition in noise around 36.36 % worse than the individuals having no disorder (group A), if they were submitted to the same communication situation with a S/N ratio of -6 to -7 dB, for example.
Another data found in literature (16) is the reference value for the S/N ratio when the evaluation is performed with earphones, which was 5.29 dB for normally hearing young adults, ranging between -2.55 and -9.22 dB with a medium standard deviation (SD) of 1.13 dB. Taking into consideration the data of the aforementioned research and roughly considering two SD based on average, a minimum value of -3 dB is found for the S/N ratios of normally hearing young adults, and it has been verified that only one individual required a more favorable S/N ratio than -3 dB.
Conversely, in the present research, when the individual results of S/N ratios were analyzed, it was evident that all the individuals in Group A recognized 50% of the speech material presented with a S/N ratio equal to or more adverse than -3 dB on both ears, and the values ranged between -3,07 and -12.8 dB on the RE and between -3.66 and -11.77 dB on the LE.
As for Group B, values of -1.04 and -8.07 dB on the RE and 0.75 e -7.25 on the LE. Only 17 (70%) of the individuals achieved this performance with a S/N ratio that is more adverse or equal to - 3 dB on the RE and 16 (66%) on the LE.
This shows that the individuals with a disorder to understand speech in noisy environments actually have a bigger difficulty in the sentence recognition task in noise, in comparison with the individuals who do not mention this difficulty at their ages and with audiological characteristics.
Understanding speech in noisy environments is a challenge for any listener. This difficulty is partially assigned to the negative effects of the noise on neural synchronization, resulting in a degaded representation of speech at cortical and subcortical levels (17).
Individuals with the same abilities to recognize speech in silence can show extremely different results in noisy environments. When the evaluation occurs in noise, in opposite to silence, several auditory channels are required to achieve the same level of speech recognition, indicating that more detailed sensorial information are necessary in adverse hearing conditions (2).
This task requires a complex group of cognitive and *perceptual abilities including auditory working memory, detection and process of *spectrum and temporal features (18, 19), in addition to the hearing abilities of background figures (20), auditory closure and selective attention (21).
Accordingly, it is considered important to evaluate the auditory decoding, because any knowledge-acquiring damage caused by the ability for an auditory integration of the sound information will make understanding speech difficult in noisy environments (22).
Accordingly, taking all these aspects into consideration and returning the results of the current researched - which proved by the LPS test that normally hearing individuals with a disorder to understand speech during noise, show a worse performance in comparison with individuals at their age without a disorder-, there may be a hypothesis that these individuals can be damaged n any of the speech processing stages and they do not succeed in performing the selective background-figure attention abilities effectively, leading to the poor performance noticed.
The objective of the speech recognition evaluation is to achieve a comprehensive understanding about how the hearing disorder impairs the different processes involved in speech understanding (23).
If there is any intrinsic reduction associated with the reduction of extrinsic redundant traces, intelligibility will be jeopardized. The speech recognition tests with a hard listening enable the auditory perceptive abilities to be evaluated and identify a central hearing alteration (21).
Due to the explanation hereinbefore, it is noticeable that evaluating the speech recognition in a way closer to day-to-day situations is crucially important. For this purpose, using both a contrasting noise requiring a complex auditory activity for the speech stimulus to be processed and tests with sentences as a stimulus, simulating communication situations in which the extension of the discourse to be recognized and the linguistic complexity are factors taken into consideration is proven to be effective to estimate the clinical disorders related to difficulty in understanding speech.
Therefore, in order to measure the real difficulty of the individual with a clinical difficulty in understanding speech in noise, even with absolutely normal hearing thresholds, the introduction of tests using sentences in noise is suggested in the daily clinical audiological evaluation. This would be the most reliable and effective way to quantify the performance of the abilities involved in this process. It is a more comprehensive approach, different from the methodology used in currently performed evaluations, which evaluate the individual only in ideal listening evaluations, i.e., in silence and with isolated words, not demonstrating the patient's actual difficulties.
It must be clear that the difficulties related to the ability to retain acoustic traces from the auditory information, focus on the relevant information and difficulty in evoking the message retained in the short-term memory will manipulate the individuals' performance in environments requiring these abilities. It is important to emphasize that this test will show, confirm and quantify the specific difficulty required by the patient, giving orientations for a possible intervention and rehabilitation. .
Based on these findings, when the result is below the expected, the patient will be submitted to further evaluations, such as hearing processing tests and electrophysiological tests whenever possible, because they intend to confirm and integrate the diagnosis so that advices and suggestions of therapeutic behavior can be given in order to help the patient minimize the clinical difficulty.
CONCLUSIONBased on the results found, it can be implied that normally hearing individuals having a disorder to understand speech in noisy environments show a bigger difficulty in the task of sentence recognition in noise in comparison with individuals not showing this difficulty, at similar ages and having similar audiological characteristics.
Therefore, the usual clinical audiological evaluation must include tests using sentences in contrasting noise situations, because this is the most reliable and efficient way to quantify individuals' performance to recognize speech when a sound environment is adverse.
Based on this evaluation, it is believed that it is necessary to survey the abilities of auditory processing when there is a clinical disorder to understand speech n noise, even when the individuals shows a normal hearing because such individuals can have some deficit in the speech processing stages.
REFERENCES1. Theunissen M, Swanepoel DW, Hanekom J. Sentence recognition in noise: Variables in compilation and interpretation of tests. Int J Audiol. 2009, 48:743-757.
2. Ziegler JC, Pech-George C, George F,Lorenzi C. Speech perception in noise déficits in dyslexia. Dev Sci. 2009, 12:732-45.
3. Paula A, Oliveira JAP, Godoy NM. Baixa discriminação auditiva em ambiente competitivo de pacientes jovens com audiograma normal. Rev Bras de Otorrinolaringol. 2000, 66(5):439-42.
4. Miranda EC, Costa MJ. Reconhecimento de sentenças no silêncio e no ruído em indivíduos jovens adultos normo-ouvintes em campo livre. Fono Atual. 2006, 8(35):4-12.
5. Henriques MO, Costa MJ. Limiares de reconhecimento de sentenças no ruído, em campo livre: valores de referência para adultos normo-ouvintes. Rev Bras de Otorrinolaringol. 2008, 74(2):188-92.
6. Freitas CD, Lopes LFD, Costa MJ. Confabilidade dos limiares de reconhecimento de sentenças no silêncio e no ruído. Rev Bras Otorrinolaringol. 2005, 71(5):624-32.
7. Costa, MJ. Listas de sentenças em português: apresentação e estratégias de aplicação na audiologia. Santa Maria: Pallotti; 1998.
8. Davis H, Silverman SR. Interpretação dos resultados da avaliação audiológica. In: Santos TMM, Russo ICP. Prática da audiologia clínica. 6ª ed. São Paulo: Cortez; 2007. p. 291-310.
9. Smoorenburg GF. Speech reception in quiet and in noise conditions by individuals with noise-induced hearing loss in relation to their tone audiogram. J Acoust Soc Am. 1992, 91(1):421-37.
10. Levitt H, Rabiner LR. Use of a sequencial strategy in intelligibility testing. J Acoust Soc Am. 1967, 42:609-12.
11. Cóser PL, Costa MJ, Cóser MJS, Fukuda Y. Reconhecimento de sentenças no silêncio e no ruído em indivíduos portadores de perda induzida pelo ruído. Rev Bras de Otorrinolaringol. 2000, 66(4):362-70.
12. Middelweerd MJ, Festen JM, Plomp R. Difficulties with speech intelligibility in noise in spite of a normal pure-tone audiogram. Int J Audiol. 1990, 29(1):1-7.
13. Soncini F, Costa MJ, Oliveira TT. Queixa de dificuldade para reconhecer a fala X limiares de reconhecimento de fala no ruído em normo-ouvintes com mais de 50 anos. Fono Atual. 2003, 26:4-11.
14 Caporali SA, Arieta AM. Reconhecimento de fala: estudo comparativo entre grupos com e sem queixa de percepção da fala. Rev Soc Bras Fonoaudiol. 2004, 9(3):129-35.
15 Wagener KC. Factors influencing sentence intelligibility in noise. Bibliotheks- und Information System der Universität Oldenburg, 2004.
16 Costa MJ, Daniel RC, Santos SN. Reconhecimento de sentenças no silêncio e no ruído em fones auriculares: valores de referência de normalidade. Rev. CEFAC; São Paulo, 2010. doi: 10.1590/S1516-18462010005000114.
17 Anderson S, Skoe E, Chandrasekaran B, Kraus N. Neural Timing is Linked to Speech Perception in Noise. The Journal of Neuroscience. 2010, 30(14):4922-26.
1) Geaduated. Phonoaudiologist.
2) Doctor. Phonoaudiologist; Assistant Professor of Federal University of Santa Maria's Phonoaudiology Department - UFSM.
3) Master. Phonoaudiologist at Phonak Hearing Center.
4) Doctor. Phonoaudiologist, Associate Professor of UFSM's Phonoaudiology Department.
5) Master. Phonoaudiologist at Sonora Hearing Center.
Institutition: Federal University of Santa Maria - UFSM. Santa Maria / RS - Brazil. Mailing address: Karine Thaís Becker - Rua Pedro Santini, 177 - apto. 109/C - Nossa Senhora de Lourdes - Santa Maria / RS - Brazil - ZIP Code: 97060-480 - Telephone: (+55 55) 8406-3292 - Email: katthais@hotmail.com
Article received on October 4, 2010. Article approved on March 27, 2011.